![]()
![]()
Once these fonts have been downloaded, IE and OE will show Unicode UTF-8 encoded data by taking the appropriate characters from these fonts.
The IME's can be removed by going to Start > Settings > Control Panel > Add/Remove Programs
For the English versions Windows XP, you can activate the IME and installation of Chinese, Japanese and Korean fonts as follows.
Table of Contents : Font Links
 ) refers to the languages of Chinese, Japanese, and Korean, though occasionally they will mean the countries China, Japan and Korea respectively, and therefore refer to the 'locale' of the script in question.
) refers to the languages of Chinese, Japanese, and Korean, though occasionally they will mean the countries China, Japan and Korea respectively, and therefore refer to the 'locale' of the script in question.
These countries use non-alphabetic characters based on the traditional Chinese script ( 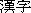 ) "hanzi", otherwise known in Japan as "kanji", and by Koreans as "hanja". For simplicity, we shall call them "characters". We can further differentiate the forms of the same characters as 'glyphs'. A 'glyph', therefore, is a variant of a character and varies depending on locale.
) "hanzi", otherwise known in Japan as "kanji", and by Koreans as "hanja". For simplicity, we shall call them "characters". We can further differentiate the forms of the same characters as 'glyphs'. A 'glyph', therefore, is a variant of a character and varies depending on locale.
Table of Contents : Font Links
Table of Contents : Font Links
32 33 34 35 36 37 38 39
! " # $ % & '
40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59
( ) * + , - . / 0 1 2 3 4 5 6 7 8 9 : ;
60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79
< = > ? @ A B C D E F G H I J K L M N O
80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99
P Q R S T U V W X Y Z [ \ ] ^ _ ` a b c
100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119
d e f g h i j k l m n o p q r s t u v w
120 121 122 123 124 125 126 127
x y z { | } ~
Table of Contents : Font Links
128 129
€
130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149
‚ ƒ „ … † ‡ ˆ ‰ Š ‹ Œ Ž ‘ ’ “ ” •
150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169
– — ˜ ™ š › œ ž Ÿ ¡ ¢ £ ¤ ¥ ¦ § ¨ ©
170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189
ª « ¬ ® ¯ ° ± ² ³ ´ µ ¶ · ¸ ¹ º » ¼ ½
190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209
¾ ¿ À Á Â Ã Ä Å Æ Ç È É Ê Ë Ì Í Î Ï Ð Ñ
210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229
Ò Ó Ô Õ Ö × Ø Ù Ú Û Ü Ý Þ ß à á â ã ä å
230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249
æ ç è é ê ë ì í î ï ð ñ ò ó ô õ ö ÷ ø ù
250 251 252 253 254 255
ú û ü ý þ ÿ
These ASCII characters may vary in appearance from machine to machine, and platform to platform, but the underlying binary code is the same, therefore, there exists portability between machines running different software operating system platforms.
Table of Contents : Font Links
Unicode uses three bytes to represent the code for one CJK character.
Table of Contents : Font Links
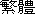 )
and simplified form "jianti" (
)
and simplified form "jianti" (  ). The characters represented so far are all fanti forms.
However, the simplified form of the characters 'jianti' ( ) is
(
). The characters represented so far are all fanti forms.
However, the simplified form of the characters 'jianti' ( ) is
( 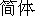 ). Other than hanzi, more modern letters for phoneticising Mandarin Chinese (and extended to other Chinese languages and dialects) are sometimes used, known as zhuyin fuhao (
). Other than hanzi, more modern letters for phoneticising Mandarin Chinese (and extended to other Chinese languages and dialects) are sometimes used, known as zhuyin fuhao ( 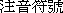 ) to indicate the pronunciation of uncommonly used characters.
) to indicate the pronunciation of uncommonly used characters.
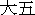 ). There are also extentions to
the Big5 character set used in Hong Kong for local dialectal characters, for example Hong
Kong Government Chinese Character Set (HK GCCS) has an 3049 character extention. This set was expanded and renamed the Hong Kong Supplementary Character Set (HKSCS).
). There are also extentions to
the Big5 character set used in Hong Kong for local dialectal characters, for example Hong
Kong Government Chinese Character Set (HK GCCS) has an 3049 character extention. This set was expanded and renamed the Hong Kong Supplementary Character Set (HKSCS).
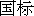 ) or GB. It adopted the use of
simplified characters shortly after the socialist government came to power. However,
Singapore Chinese also use simplified characters. Simplified characters are derived from
handwritten forms of traditional characters, and a great many traditional characters are
left unchanged after its inception because they were never simplified.
) or GB. It adopted the use of
simplified characters shortly after the socialist government came to power. However,
Singapore Chinese also use simplified characters. Simplified characters are derived from
handwritten forms of traditional characters, and a great many traditional characters are
left unchanged after its inception because they were never simplified.
Another encoding method used for simplified Chinese is known as 'Hanzi'. It is primarily used as a seven bit code, that is, it is entirely composed of characters from the original ASCII. It is easy to spot, since it always begins with the tild and curly brackets, and ends in a curly bracket and another tilde.
Table of Contents : Font Links
In general, Japanese contains characters that may not be found in the Chinese encodings.
These Japanese only characters are mainly 'kokuji' ( 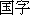 ) or national
characters of Japan. These occur mainly in the names of birds, fishes and other animals. Japanese has two syllabaries, known as hiragana
(
) or national
characters of Japan. These occur mainly in the names of birds, fishes and other animals. Japanese has two syllabaries, known as hiragana
( 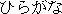 ) and katakana (
) and katakana ( 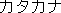 ) respectively,
(with each word in its own syllabary).
) respectively,
(with each word in its own syllabary).
Table of Contents : Font Links
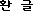 ), for their language
made up of basic letters known as jamo (
), for their language
made up of basic letters known as jamo ( 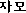 ).
).
There are also characters solely found only in Korean, known as gugja
( 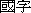 ) which mainly appears in placenames.
) which mainly appears in placenames.
Table of Contents : Font Links
There are two forms of Unicode encodings, UTF-7 which is a 7-bit encoding, and UTF-8 which is an 8-bit encoding.
Table of Contents : Font Links
![]() I wish to thank Thomas Chan for his suggestions and the link to the HKSCS site.
I wish to thank Thomas Chan for his suggestions and the link to the HKSCS site.
![]()
This page was created on Wednesday 6th December 2000.
It was last updated on Monday 31st March 2003.